
Modern software development is a fast and iterative process aimed at delivering amazing products and experiences to customers. To get the most out of our time, we rely a lot on the tools and utilities we use every day.
If you’re familiar with any modern popular programming language, you’re likely adept at using tools such as an integrated development environment (IDE). An IDE comes with a series of tools including:
- a syntax highlighter (which marks up your code in different colors to make it easier to read)
- a linter and/or static analyzer (to help you write better code by letting you know when you’ve made mistakes at compile time)
These tools all share a very common but often overlooked trait; they parse your code to infer meaning as part of their function. It used to be the case that writing a good language recognizer and parser was a rather complicated affair, but today there are several great tools that help do a lot of the work for you.
ANTLR or ANother Tool for Language Recognition is a lexer and parser generator aimed at building and walking parse trees. It makes it effortless to parse nontrivial text inputs such as a programming language syntax.
In this post, we’ll get into the basics of getting ANTLR up and running in a dev environment.
Setting up an ANTLR project
The easiest way to set up a project using ANTLR is by using a Gradle plugin. This holds true even if you plan on targeting a language other than Java. Here’s a sample build script to get started with.
Building a Grammar
Before we begin generating a lexer and parser for our hypothetical syntax or language we must describe its structure by putting together a grammar. ANTLR 4 grammars are typically placed in a *.g4 file inside of the antlr source folder.
ANTLR 4 allows you to define lexer and parser rules in a single combined grammar file. This makes it really easy to get started. To get familiar with working with ANTLR, let’s take a look at what a simple JSON grammar would look like and break it down.
First, we begin by declaring the name of the grammar using the grammar keyword. It must match the name of the *.g4 file.
Next, we define a header and package name which will be placed at the start of the generated parser class. This will allow us to designate a package to import in our java code.
We define an IDENTIFIER token as a lexer rule and provide a description to match it:
Lexer rules always start with an uppercase letter. These rules focus on defining the tokens that will form the foundation of your parser rules. This should look somewhat familiar to anyone that’s worked with regular expressions.
The A-Z denotes any letter between A and Z, a-z denotes any letter between a and z, while 0-9 denotes any number between 0 and 9. Rules may also have a suffix operator that indicates how often they are expected to appear. + means it may be present at least once (one or more). This means that our IDENTIFIER rule will match any combination of uppercase, lowercase and integer characters but not an empty character.
By default, the lexer tokenizes everything including whitespace characters. This means that you’d have to define whitespace and every possible place in which whitespace can be used in your grammar. However, since JSON is not whitespace sensitive, it’s pretty handy not to have to explicitly deal with whitespace characters. We can write a lexer rule to deal with this.
Here we define a whitespace token consisting of one or more spaces, tabs, and line breaks and having ANTLR skip over them.
Parser rules start with a lower case. These rules focus on helping you build an abstract syntax tree out of your parsed tokens. In our JSON parser example, we can construct a rule to parse a simple JSON object this way.
We define a JSON object as beginning with a { and ending with a }. It can optionally contain key value pairs delimited by a ,. Since values in the JSON specification can also contain other JSON objects. We can recursively define the value component of our key-value pair to accept either a primitive or jsonObject.
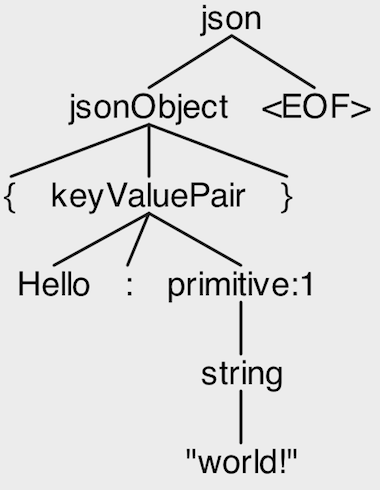
So now that we have our grammar we can try parsing some sample input. Given the following JSON snippet:
Our grammar will output the following AST:
ANTLR and BrightScript
Writing your own lexer and parser can be quite difficult and time consuming. ANTLR makes it easy to get a quick jump start writing your own parser. It’s a powerful tool that can be used to parse almost anything from the most benign structured inputs to fully-featured compilers and interpreters.
At WillowTree we’ve been using ANTLR to develop our own BrightScript linter to help our Roku team write better BrightScript code. We plan to open source in the near future as the tool becomes more mature. In a future blog post we’ll walk through how we’re using ANTLR to parse BrightScript as well as some of the technical challenges involved in using ANTLR at scale.
You can find the full code example used in this guide here.
